每日题解:LeetCode 10. 正则表达式匹配
2020-06-21
题目描述
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配。
'.' 匹配任意单个字符
'*' 匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
说明:
s 可能为空,且只包含从 a-z 的小写字母。
p 可能为空,且只包含从 a-z 的小写字母,以及字符 . 和 *。
示例 1:
输入:
s = "aa"
p = "a"
输出: false
解释: "a" 无法匹配 "aa" 整个字符串。
示例 2:
输入:
s = "aa"
p = "a*"
输出: true
解释: 因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
示例 3:
输入:
s = "ab"
p = ".*"
输出: true
解释: ".*" 表示可匹配零个或多个('*')任意字符('.')。
示例 4:
输入:
s = "aab"
p = "c*a*b"
输出: true
解释: 因为 '*' 表示零个或多个,这里 'c' 为 0 个, 'a' 被重复一次。因此可以匹配字符串 "aab"。
示例 5:
输入:
s = "mississippi"
p = "mis*is*p*."
输出: false
解法
int sLength = s.length();
int pLength = p.length();
boolean[][] dp = new boolean[sLength + 1][pLength + 1];
dp[0][0] = true;
for (int i = 0; i <= sLength; i++) {
for (int j = 1; j <= pLength; j++) {
if (p.charAt(j - 1) == '*') {
dp[i][j] = dp[i][j - 2];
if (matches(s, p, i, j - 1)) {
dp[i][j] = dp[i][j] || dp[i - 1][j];
}
}
else {
if (matches(s, p, i, j)) {
dp[i][j] = dp[i - 1][j - 1];
}
}
}
}
return dp[sLength][pLength];
}
public boolean matches(String s, String p, int i, int j) {
if (i == 0) {
return false;
}
if (p.charAt(j - 1) == '.') {
return true;
}
return s.charAt(i - 1) == p.charAt(j - 1);
}
解题思路
DP(动态规划)
根据题目的符号的类型,可以分为三种情况,我们使用i表示s的字符的下标,j表示p字符的下标
字母
当遇到这种情况的时候,比较简单,直接对比两个字符就可以了,即s.charAt(i) == p.charAt(j);
.符号
当遇到.进行匹配时 ,因为.,只能表示一个字符,所以和第一个单字母情况类似,只要p.charAt(j)=".",就认为匹配上了即s.charAt(i) == p.charAt(j);
*符号
由于*符号前一个元素匹配零次,或者多次情况(包括一次),这里就会遇到多种情况
- 零次
s = "aabb"
p = "c*a*b"
题目中的例子,c*在s字符匹配不到任何字符,就需要往后再寻找下一个字符是否满足当前i字符
即s.charAt(i) == p.charAt(j+2);或者 s.charAt(i) == p.charAt(j+3);...直到找到字母位置匹配,相当于当前的c*不考虑‘
- 一次或者多次
第一次 s.charAt(i) == p.charAt(j-1);
第2次 s.charAt(i+1) == p.charAt(j-1);
第3次 s.charAt(i+2) == p.charAt(j-1);
....
以上的i,j在两个字符长度相等的情况下,实例的测试用例当中,两个字符长度并不相等,由于 *符号可以表示多个字符
假设 dp[i][j]表示 s 的前 i 个字符与 p 中的前 j 个字符是否能够匹配,已知 dp[i-1][j-1] =true,表示之前的字符已经匹配
-
第一种情况 j是小写字母或者.符号
如果s[i]=p[j],dp[i][j]=dp[i-1][j-1],这里如果 .符号,只要判断p.charAt(j - 1) == '.' && dp[i-1]=字母
如果s[i]!=p[j],dp[i][j]=false -
第二种 情况 j是*符号
前一个字符没有匹配dp[i][j]=dp[i][j-2],这里我们需要往前面寻找j-2位置是否匹配上
比如:
s = "aab"
p = "c*a*b"
虽然c*没有匹配上,可以看做匹配0次 c,相当于直接去掉 c*,回到初始化的结果,true,代码需要初始化dp[0][0]=true;
换个例子比较清晰点
s = "ab"
p = "abc*"
虽然c*没有匹配上,但是,之前的匹配结果还是true的
匹配一次,i位置的字符和j-1位置字符匹配
dp[i][j]=dp[I][j-1]
匹配多次,s多个字符和j字符匹配
一次 :dp[i][j]=dp[i-1][j] 如果 if s[i]=p[j−1]
两次 :dp[i][j]=dp[i-2][j] 如果 if s[i−1]=s[i]=p[j−1]
三次 :dp[i][j]=dp[i-3][j] 如果s[i−2]=s[i−1]=s[i]=p[j−1]
⋯⋯
dp[i-1][j]
最后归纳一下
// 没有匹配的情况
dp[i][j] = dp[i][j-2]
// 单个字符匹配的情况
or dp[i][j] = dp[i][j-1]
// 多个字符匹配的情况
or dp[i][j] = dp[i-1][j]
总结
来自官方提交的DP总结
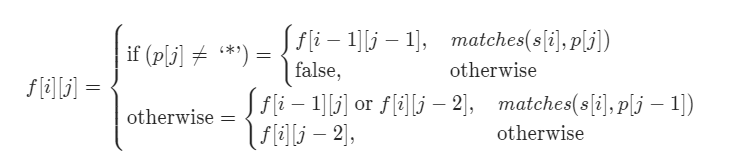
如果我在下次再遇到这种题目,我选择不做(主要是不会,哈哈哈)!!
JAVA源码实现
JAVA中的Pattern.matches()是否也这么复杂?源码中使用了责任链模式,是将正则表达式解析成不同的部分的,使用了不同类型的NODE进行包装,以单链表分方式关联。
比如mis*is*p*.为例
就会分成四个类型的
Slice类型(字符类型): mi
Curly类型(*符号): s*,s*,p*
Single类型(单个字母): i
Dot 类型(.符号): .
每种类型的最顶级的父类都是java.util.regex.Pattern.Node,最后正则表达式会保存在java.util.regex.Pattern#matchRoot的单链表中,上面的例子保存为以下的顺序
Slice(mi)->Curly(s) ->Single(i)->Curly(s)-> Curly(p)->Dot()->
每个类型都重写了boolean match(Matcher matcher, int i, CharSequence seq) {},当matchRoot不为空时,会依次调用match方法会一一对比字符串是否相等
比如Slice类型,就是单个字符进行比较
boolean match(Matcher matcher, int i, CharSequence seq) {
int[] buf = buffer;
int len = buf.length;
for (int j=0; j<len; j++) {
if ((i+j) >= matcher.to) {
matcher.hitEnd = true;
return false;
}
if (buf[j] != seq.charAt(i+j))
return false;
}
return next.match(matcher, i+len, seq);
}