项目工具:线上"假死“问题解决(Jstack工具分析,脚本监控服务)
2021-03-01
问题
项目在正式上线后,偶发性出现项目的"假死"的问题,项目无法响应前端的请求,一开始,架构师查询到存在大量锁表的情况,去掉了一些长时间任务的更新的事务,同时提高了JVM的-Xmx和-Xms的大小,第一天虽然情况有所缓解,在第二天访问量上去后,还是出现了假死的问题。于是,在顶着客户在抱怨的情况下,我使用Jstack保存了当时的堆信息,分析当时项目的线程情况。
jstack是java虚拟机自带的一种堆栈跟踪工具。jstack用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息
日志分析
值得关注的线程状态有(加粗)
- 死锁, Deadlock
- 执行中,Runnable
- 等待资源, Waiting on condition
- 等待获取监视器, Waiting on monitor entry
- 暂停,Suspended
- 对象等待中,Object.wait() 或 TIMED_WAITING
- 阻塞, Blocked
- 停止,Parked
分析了日志中大量出现了线程处于Blocked的状态,出现阻塞位置都在一行代码,于是,这应该是当时假死的问题所在
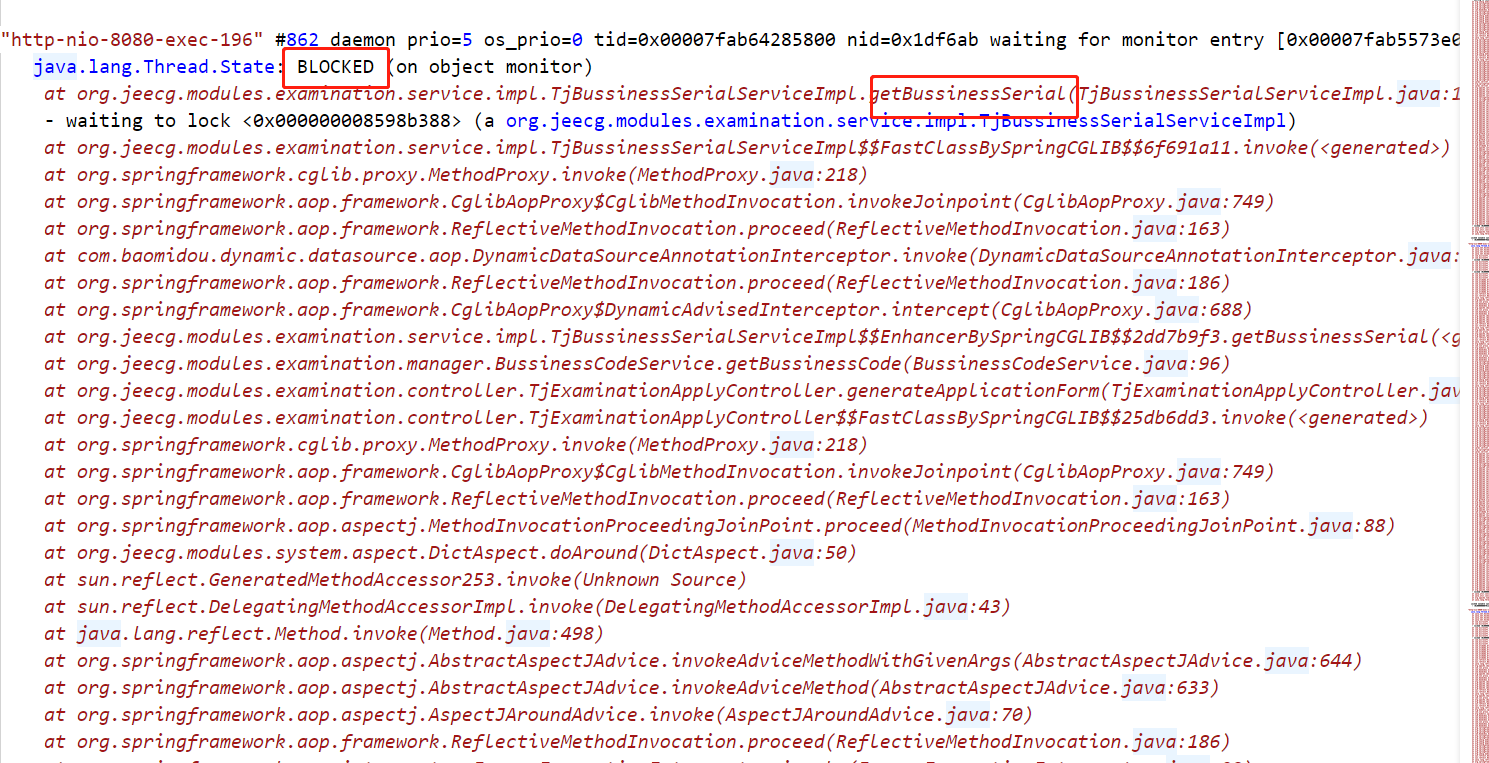
找到相应的代码位置
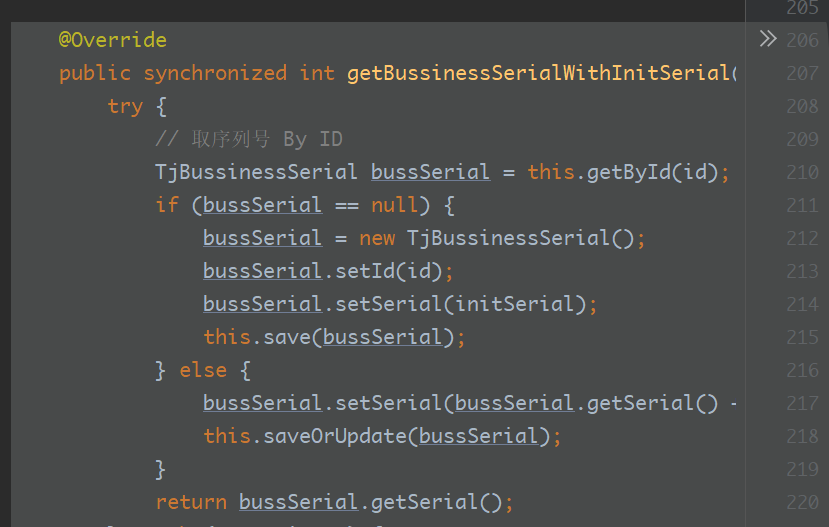
这是获取序列号的代码,并且方法加了synchronized,既然,使用了synchronized同步,为什么还是出现了相互阻塞的问题?
个人理解,查询了代码这里的传入参数id,在代码中多处出现了

- 其中一个线程,可以看到其中一个线程,使用了updateById更新;其他线程则是阻塞在getById这个方法,这个几个方法的
id都是AP,在并发情况下,则出现了相互抢资源的问题 - synchronized锁非静态方法属于this锁,这里传入的
AP在java的常量池都是一个存储位置都一样,出现了相互等着释放的问题
解决方法
避免并发抢资源的问题,那就保证获取序列号的地方,只能一个示例能获得到当前对象id的锁,之前在项目中,写过Redis锁,为了快速解决问题,直接将代码copy复制过来,使用redis锁保证多线程获取同一个资源的互斥
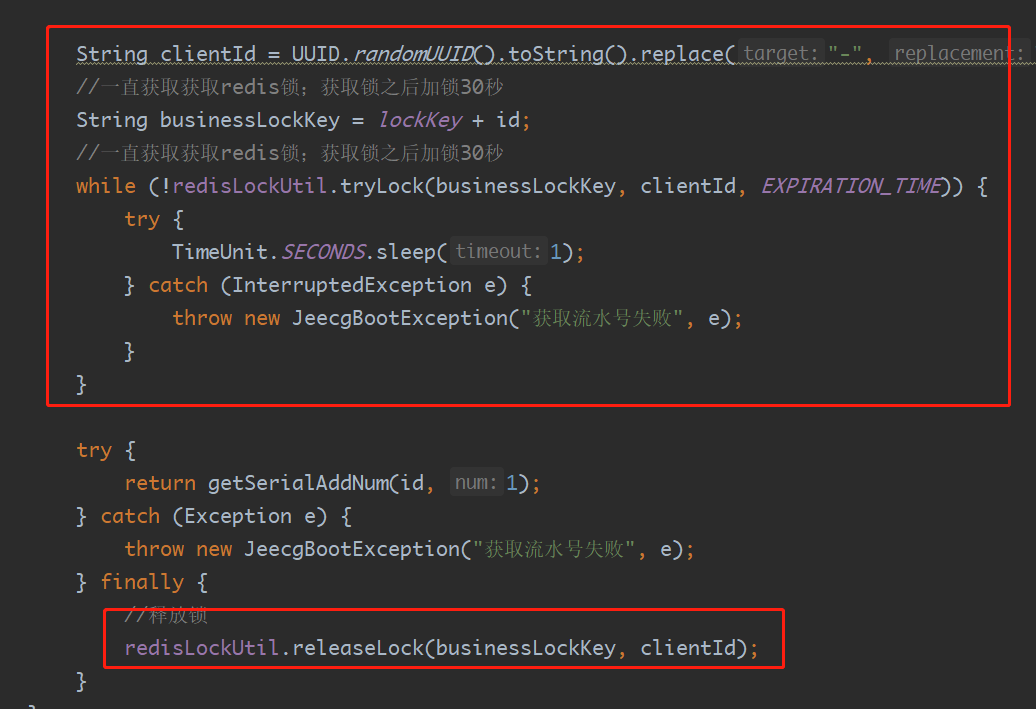
Redis锁
@Component
@Slf4j
public class RedisLockUtil {
/**
* lua脚本删除锁
*/
private static final String RELEASE_LOCK_LUA_SCRIPT = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
private static final Long RELEASE_LOCK_SUCCESS_RESULT = 1L;
@Autowired
private StringRedisTemplate redisTemplate;
/**
* RedisLockUtil:: tryLock
* <p>获取redis的锁
* <p>HISTORY: 2020/11/4 liuha : Created.
*
* @param lockKey 锁的id
* @param clientId 业务自定义的id
* @param seconds 过期时间(秒)
* @return Boolean true 获取成功:false 获取失败
*/
public Boolean tryLock(String lockKey, String clientId, long seconds) {
log.info("tryLock lock:{key:{},clientId:{}}", lockKey, clientId);
return redisTemplate.opsForValue()
.setIfAbsent(lockKey, clientId, seconds, TimeUnit.SECONDS);
}
/**
* RedisLockUtil:: releaseLock
* <p>释放redis的锁
* <p>HISTORY: 2020/11/4 liuha : Created.
*
* @param lockKey 锁的id
* @param clientId 业务自定义的id
* @return Boolean true 释放成功:false 释放失败
*/
public Boolean releaseLock(String lockKey, String clientId) {
log.info("release lock:{key:{},clientId:{}}", lockKey, clientId);
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>(RELEASE_LOCK_LUA_SCRIPT, Long.class);
Long result = redisTemplate.execute(redisScript, Collections.singletonList(lockKey), clientId);
return Objects.equals(result, RELEASE_LOCK_SUCCESS_RESULT);
}
}
扩展
由于这次,正好遇到了系统"假死"出现时候,才能使用Jstack保存下来日志,分析解决问题,虽然分析的原因可能不太准确,但是最终的效果,"假死"的问题不再出现。
如果能自动监控端口的服务,自动保存当时的线程情况日志?于是,便结合网上的资料,使用python写了自动监控服务异常的脚本,
# -*- coding: utf-8 -*-
import time
import subprocess as cm
import os
# 执行方法
def executeFun():
# port 端口号
port = '8080'
# 获取进程命令 pid_comm ;
# netstat -ntpl|grep port : 获取端口号port 的进程信息
# awk '{printf $7}' : 取第七列
# cut -d/ -f1 : 以 / 分割后取第一个值
pid_comm = 'netstat -ntpl|grep ' + port + '|awk \'{printf $7}\'|cut -d/ -f1'
# 取得进程 pid
pid = cm.getoutput(pid_comm)
if (pid == ''):
print('no pid')
return
# 获取cup, mem百分比命令
# top -p pid -n1 : 获取进程 pid 的top 信息,只刷新一次。
# sed -n '8p' : 获取第8行
# awk '{printf $9}' : 获取第9列
cup_comm = 'top -b -p ' + pid + ' -n1|sed -n \'8p\'|awk \'{printf $9}\''
# 内存
mem_comm = 'top -b -p ' + pid + ' -n1|sed -n \'8p\'|awk \'{printf $10}\''
# 取得cpu 占用百分比
cpu_perc_str = cm.getoutput(cup_comm)
# 内存
mem_perc_str = cm.getoutput(mem_comm)
# 转成数字类型
cpu_perc = float(cpu_perc_str)
mem_perc = float(mem_perc_str)
print(cpu_perc)
print(mem_perc)
# 获取时间串
time_str = time.strftime("%Y%m%d%H%M%S", time.localtime())
# 日志存放目录
log_dir = './log/'
# 百分比大于100执行
if (cpu_perc >100.0):
# 保存 jstack 日志
jstack_comm = 'jstack -l ' + pid + ' >> ' + log_dir + 'gc_' + time_str + '_cpu_' + cpu_perc_str + '.log'
os.system(jstack_comm)
# 百分比大于20执行
elif (mem_perc >20.0):
# 保存 jstack 日志
jstack_comm = 'jstack -l ' + pid + ' >> ' + log_dir + 'gc_' + time_str + '_mem_' + mem_perc_str + '.log'
os.system(jstack_comm)
# 删除7天前的文件
rm_log_comm = 'find ' + log_dir + ' -mtime +7 -type f -name "*.log" -exec rm -f {} \;'
os.system(rm_log_comm)
if __name__ == '__main__':
while (True):
executeFun()
# 延迟10秒
time.sleep(10)
监控的效果